在数字化时代,数据已成为企业运营的核心驱动力。构建一个高效、可靠的数据运营体系,数据处理与存储服务是其坚实的地基。本文将从零开始,手把手教你如何规划和搭建这一关键组成部分,为你的数据运营体系保驾护航。
第一步:明确业务目标与数据需求
在开始技术搭建之前,首先要回归业务本质。你需要回答几个关键问题:
- 业务目标是什么? 是提升用户留存、优化营销ROI,还是实现智能风控?目标决定了你需要关注哪些数据。
- 需要哪些数据? 明确数据来源(如用户行为日志、业务数据库、第三方API)和数据类型(结构化、半结构化、非结构化)。
- 数据如何被使用? 是用于实时监控、即席分析、批量报表,还是机器学习训练?这决定了数据处理流程的时效性要求。
第二步:设计数据处理流程(数据管道)
数据处理流程是将原始数据转化为可用资产的流水线,通常包括以下几个核心环节:
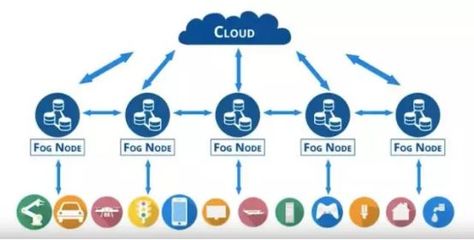
- 数据采集与接入:
- 工具选择: 根据数据源类型,选择合适的技术。例如,使用
Logstash、Flume收集日志,用Kafka作为高吞吐量的消息队列进行数据缓冲,或通过Sqoop、DataX进行数据库同步。
- 关键原则: 确保数据接入的稳定性、及时性和完整性。建议采用异步、解耦的设计,避免对源系统造成压力。
- 数据清洗与预处理:
- 核心任务: 处理数据中的缺失值、异常值、重复记录,并进行格式标准化。这是保障数据质量的关键一步。
- 实现方式: 可以在流处理(如
Apache Flink、Spark Streaming)或批处理(如Apache Spark、Hive SQL)环节中编写清洗规则。
- 数据转换与集成:
- 核心任务: 将来自不同源头的数据按照统一的业务模型(如维度建模)进行关联、聚合和衍生计算,形成主题明确的数据宽表或数据立方体。
- 工具与层: 这通常在数据仓库(如
Snowflake、Amazon Redshift、阿里云MaxCompute)或数据湖(如Apache Hudi、Delta Lake)的“数据整合层”完成。
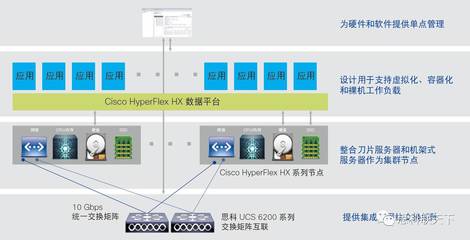
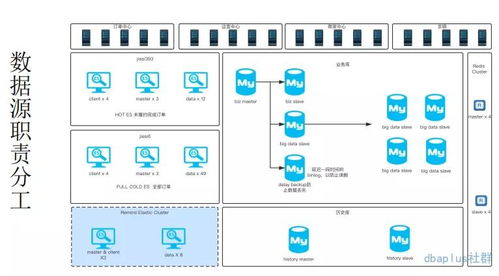
- 数据存储与分层:
- 构建分层架构: 这是数据存储设计的核心思想,通常分为:
- ODS(操作数据存储层): 存放原始、未加工的细节数据,保留历史,与源结构基本一致。
- DWD/DIM(明细/维度层): 对ODS层数据进行清洗、标准化和维度退化后形成的明细事实表和维度表。
- DWS/ADS(汇总/应用层): 基于明细层,按主题进行轻度或重度聚合,形成可直接用于分析报表或数据应用的数据集。
- 技术选型:
- 大数据量、低成本存储: 对象存储(如AWS S3、阿里云OSS)或HDFS作为数据湖底座。
- 高性能交互式查询: 云数据仓库或MPP数据库(如ClickHouse)。
- 实时查询: 可考虑列式存储(如HBase)或实时数仓(如Apache Doris)。
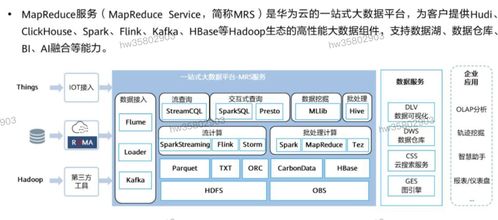
第三步:选择与实施技术栈
基于流程设计,选择合适的技术组件。一个典型的现代技术栈可能包括:
- 数据集成与流处理: Apache Kafka, Apache Flink
- 批处理与计算引擎: Apache Spark, Apache Hive
- 数据存储与湖仓: 云对象存储 + Delta Lake/Hudi, 或云原生数据仓库(Snowflake, BigQuery)
- 任务调度与编排: Apache Airflow, DolphinScheduler
- 元数据与数据治理: Apache Atlas, DataHub
实施要点: 从小范围试点开始,验证流程的可行性和性能,再逐步扩展到全业务域。优先保障核心业务线的数据需求。
第四步:建立数据质量管理与运维体系
数据处理与存储服务并非一劳永逸,需要持续的运营。
- 数据质量监控: 定义关键数据的质量规则(如完整性、准确性、一致性、时效性),并设置自动化监控和告警。
- 数据血缘与资产目录: 建立数据血缘图谱,追踪数据从来源到应用的完整链路,便于问题排查和影响分析。构建可检索的数据资产目录,提升数据发现和理解的效率。
- 运维监控: 对数据管道的健康度(延迟、吞吐量、错误率)、计算资源、存储成本进行全方位监控。
- 安全与权限: 实施基于角色(RBAC)或属性(ABAC)的精细权限控制,对敏感数据进行脱敏或加密。
第五步:迭代与优化
数据运营体系是不断生长和演进的。随着业务变化和技术发展,你需要:
- 响应新的业务需求, 如增加实时数据处理能力。
- 优化性能与成本, 例如通过数据生命周期管理(冷热分层、自动归档)降低存储开销,或优化计算任务减少资源消耗。
- 提升数据易用性, 通过更好的数据模型、API服务或数据产品,让业务人员和分析师能更便捷地获取数据价值。
###
搭建数据处理与存储服务是一项系统工程,需要将业务洞察、架构设计、技术选型和持续运营紧密结合。遵循“业务驱动、分层解耦、质量优先、迭代演进”的原则,你就能从0到1,构建出一个能够支撑企业高效决策和智能创新的坚实数据基座。记住,这个基座的终极目标,是让数据流得通、存得好、用得上,最终驱动业务增长。