随着云计算和大数据技术的快速发展,传统Hadoop架构在资源利用、扩展性和运维成本方面面临挑战。存算分离作为一种新兴架构模式,结合云原生技术,为Hadoop生态系统带来了革命性的优化。本文将详细解析Hadoop存算分离在云原生环境下的实现方式及其在数据存储管理和数据处理服务中的应用。
一、Hadoop存算分离的基本概念
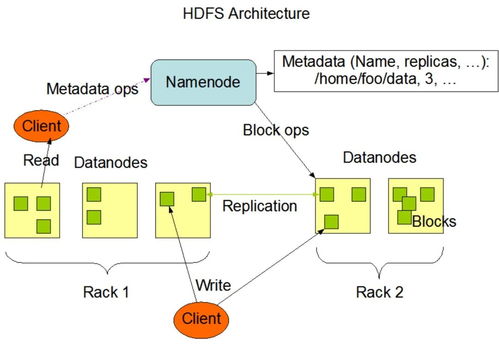
存算分离是指将数据存储与计算资源解耦,使两者可以独立扩展和管理。在传统Hadoop架构中,HDFS(Hadoop分布式文件系统)与计算框架(如MapReduce、Spark)紧密耦合,存储和计算资源绑定在同一集群节点上。这种架构虽然简化了数据本地性处理,但也导致了资源利用率低、扩展不灵活等问题。
存算分离通过将数据存储迁移到独立的存储系统(如对象存储、云存储服务),使计算节点可以按需弹性伸缩,大幅提升了资源利用效率和系统灵活性。
二、Hadoop存算分离的云原生实现方式
- 存储层解耦:采用云原生存储服务(如AWS S3、Azure Blob Storage、阿里云OSS)替代HDFS作为主要数据存储。这些服务提供高可用、高耐久性和无限扩展能力,同时降低了运维复杂度。
- 计算层优化:计算框架(如Spark、Flink)通过适配器或插件直接访问云存储,支持数据读取和写入。例如,Spark可以通过Hadoop S3A连接器直接访问S3存储,实现无缝数据访问。
- 元数据管理:使用独立的元数据服务(如Apache Hudi、Delta Lake)或云原生数据库(如AWS Glue Data Catalog)管理数据表和分区信息,确保数据一致性和事务支持。
- 资源调度与编排:借助Kubernetes等容器编排工具,动态调度计算任务,实现资源的弹性分配和高效利用。计算节点可以按需创建和销毁,避免资源浪费。
三、存算分离在数据存储管理中的优势
- 成本优化:存储与计算独立计费,用户可以根据实际需求选择存储类型(如冷热分层)和计算规模,避免过度配置。
- 弹性扩展:存储容量和计算能力可以分别扩展,不受彼此限制。例如,存储可以无限扩展,而计算资源可以根据负载动态调整。
- 高可用与容灾:云存储服务通常内置多副本和跨区域备份机制,提供更高的数据可靠性和灾难恢复能力。
- 运维简化:无需维护HDFS集群,减少了节点故障恢复、数据平衡等运维负担。
四、存算分离在数据处理服务中的应用
- 批处理任务:大数据批处理作业(如ETL、数据分析)可以直接从云存储读取数据,利用弹性计算资源快速完成处理,并将结果写回云存储。
- 流式处理:实时数据处理框架(如Flink、Kafka)可以与云存储集成,实现流批一体数据处理,支持实时数据入库和离线分析。
- 交互式查询:通过Presto、Trino等查询引擎,用户可以直接对云存储中的数据进行交互式查询,无需数据迁移,提升分析效率。
- 机器学习与AI:存算分离架构支持大规模训练数据的存储和分布式计算,为机器学习模型训练和推理提供高效的数据基础设施。
五、挑战与最佳实践
尽管存算分离带来诸多优势,但也面临一些挑战,如数据一致性、网络延迟、安全性等。为应对这些挑战,建议采取以下最佳实践:
- 选择高性能网络和存储服务,减少数据访问延迟。
- 使用数据格式优化(如ORC、Parquet)和缓存技术提升读写性能。
- 实施严格的数据权限管理和加密机制,保障数据安全。
- 定期进行数据备份和一致性校验,确保数据完整性。
Hadoop存算分离结合云原生技术,为大数据处理提供了更灵活、高效和经济的解决方案。随着云原生生态的不断完善,存算分离将成为大数据平台架构的主流趋势,助力企业在数字化转型中实现数据驱动的业务创新。