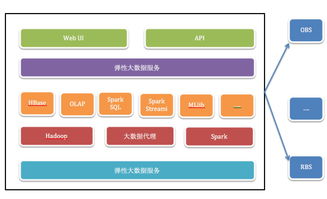
在当今数据驱动的时代,弹性大数据架构已成为企业应对海量、多源、实时数据挑战的核心解决方案。其核心优势在于能够根据负载动态伸缩资源,实现成本与性能的最优平衡。本文将通过一张架构图,为您清晰解析弹性大数据架构中数据处理与存储服务的关键组件与流程。
架构全景图核心层次
一张典型的弹性大数据架构图通常自上而下分为四层:数据摄入层、数据处理与计算层、数据存储层以及统一管理与调度层。各层通过弹性云服务无缝衔接,共同构成一个灵活、高效的数据价值链。
数据处理服务:流批一体的计算引擎
在数据处理层,弹性架构的核心是计算与资源分离。计算服务(如Spark、Flink处理集群)与底层资源(虚拟机、容器)解耦,通过Kubernetes等容器编排平台实现秒级弹性伸缩。
- 实时流处理:采用Flink、Spark Streaming等引擎,对消息队列(如Kafka)中的数据进行实时过滤、聚合与风控分析,结果可实时写入数据库或送至下游应用。
- 批处理与数据湖分析:利用Spark、Hive on Tez等引擎,对存储在对象存储(如S3、OSS)或数据湖中的历史数据进行ETL清洗、复杂分析与机器学习模型训练。计算集群按需启动,任务完成后自动释放资源,实现成本优化。
- 交互式查询:通过Presto、Impala等即席查询引擎,为用户提供对海量数据的亚秒级快速查询能力,计算资源池可根据并发查询量自动扩缩容。
数据存储服务:分层、多模的弹性存储
弹性架构的存储层遵循“热温冷”数据分层策略,并采用多模存储以适配不同数据类型与访问模式。
- 数据湖存储(核心存储层):通常基于高可扩展、低成本的对象存储(如AWS S3、Azure Blob Storage、阿里云OSS)构建企业级数据湖,存储所有原始与加工后的数据,是批处理与分析作业的主要数据源。其无限扩展的特性是弹性的基石。
- 高速缓存与索引存储:为满足低延迟访问需求,使用Redis、Memcached作为热数据缓存;使用Elasticsearch提供全文检索与日志分析能力。这些服务通常以托管集群形式提供,支持垂直与水平弹性伸缩。
- 实时/分析型数据库:流处理结果或聚合后的数据可写入云原生数据库,如时序数据库TSDB用于监控数据,分析型数据库ClickHouse或云数据仓库(如Snowflake、BigQuery、MaxCompute)用于支撑BI报表与即席分析。这些服务大多具备存储与计算独立伸缩的能力。
- 消息队列与日志存储:Kafka作为实时数据管道中枢,其托管服务(如MSK、Confluent Cloud)可平滑处理流量峰值。操作日志、审计日志可持久化至专为日志优化的存储服务(如S3+Iceberg格式,或ELK套件)。
统一管理与调度:弹性的“大脑”
弹性调度由工作流编排器(如Airflow、AWS Step Functions)和资源管理器共同完成。它们监控队列堆积、资源利用率等指标,自动触发计算集群的扩容或缩容策略,并协调数据处理DAG中各个任务的依赖与执行。
核心弹性价值体现
通过上述组件协同,该架构实现了:
- 资源弹性:应对业务波峰波谷,避免资源闲置与瓶颈。
- 成本优化:采用按需付费与Spot实例等策略,显著降低TCO。
- 敏捷开发:存储与计算解耦,使数据团队能独立、快速地迭代数据处理逻辑。
- 架构韧性:云服务的多可用区部署与高可用设计保障了业务连续性。
###
总而言之,一张清晰的弹性大数据架构图,生动展现了以对象存储为中心的数据湖、弹性可扩缩的计算集群以及多样化的数据存储服务如何有机整合。它不仅是技术组件的罗列,更描绘了一条从数据流入到价值产出的高效、经济且敏捷的弹性管道。企业构建此类架构时,应紧密结合自身业务场景,在数据处理时效性、存储成本与查询性能之间找到最佳平衡点。