TiDB作为新一代的分布式数据库,其架构设计巧妙融合了传统关系型数据库与NoSQL系统的优势,提供了强大的数据处理与存储服务。本文将从架构与核心特性两个维度,深入剖析TiDB如何满足现代应用对数据服务的苛刻要求。
TiDB整体架构:分层解耦,弹性扩展
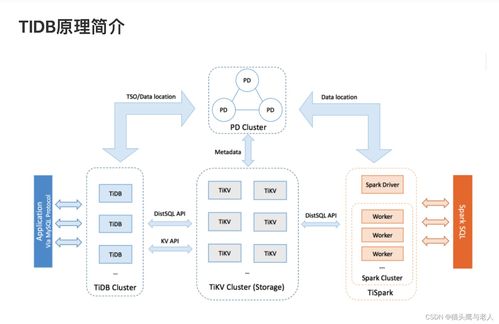
TiDB的架构主要由三个核心层构成,各司其职,协同工作:
- TiDB Server(计算层):
- 这是无状态的计算节点,负责接收SQL请求,进行SQL解析、优化,并生成分布式执行计划。
- 它不存储数据,只负责数据处理。这种设计使得TiDB Server节点可以轻松地水平扩展,以应对高并发的查询负载。
- 对应用层而言,它完全兼容MySQL协议和语法,使得迁移和使用成本极低。
- TiKV Server(存储层):
- 这是TiDB的核心存储引擎,一个分布式、高可用的键值存储系统。数据以Region为基本单位(默认96MB)自动分片,并利用Raft一致性协议在多个TiKV节点间实现数据的高可靠复制与强一致性。
- TiKV采用多副本机制,任何副本的故障都不会影响数据可用性。其分布式事务模型(基于Google Percolator)提供了完整的ACID事务支持,特别是跨节点的分布式事务。
- PD Server(调度层):
- Placement Driver (PD) 是整个集群的“大脑”,负责管理集群的元数据、TiKV节点和Region的调度,以及为分布式事务分配全局唯一且单调递增的时间戳。
- PD通过持续监控集群状态,自动进行负载均衡、故障恢复(如Leader重选、副本补全)和热点Region调度,确保集群始终处于健康、平衡的状态。
这三层分离的架构,实现了存储与计算的分离,允许各自独立、弹性地扩缩容,为云原生部署提供了理想的灵活性。
核心特性:面向数据处理与存储服务的强大能力
基于上述架构,TiDB展现出以下关键特性,使其成为处理海量数据与高并发事务的理想选择:
1. 水平扩展与高可用性
- 无缝水平扩展:无论是计算资源(TiDB Server)还是存储与IOPS能力(TiKV),都可以通过简单地添加节点来实现线性提升。业务无需停机或手动分片。
- 金融级高可用:数据在TiKV层通过Raft协议多副本(通常3副本)存储,任一节点甚至整个数据中心故障,都能自动、快速地进行故障转移与数据恢复,保证RPO=0, RTO通常小于30秒。
2. 强一致性与分布式事务
- 完整的ACID事务:TiDB支持跨节点的分布式事务,默认隔离级别为可重复读(Snapshot Isolation),满足金融、交易等核心业务对数据一致性的严苛要求。
- 乐观锁与悲观锁模式:为不同业务场景提供了灵活的事务模型选择,优化了高并发冲突下的性能。
3. 实时HTAP混合负载处理
- 行列混合存储:这是TiDB在数据处理服务上的革命性特性。除了行存引擎TiKV,TiDB引入了列存引擎TiFlash作为TiKV的实时分析副本。
- 同一份数据,两种处理方式:数据通过Raft Learner协议从TiKV实时同步到TiFlash,确保行存与列存的数据强一致。用户无需进行复杂的ETL,即可在同一套系统中同时进行高并发的在线事务处理(OLTP)和复杂的实时数据分析(OLAP),真正实现“一库多用”。
4. 云原生与生态兼容
- 与Kubernetes深度集成:TiDB Operator项目使得TiDB在K8s上的部署、管理和运维完全自动化,具备极致的弹性能力。
- 高度兼容MySQL生态:兼容MySQL 5.7协议和大多数语法,现有应用、工具(如Navicat、ORM框架)和MySQL运维经验可以平滑迁移,极大降低了采用门槛。
5. 简化的运维与智能调度
- 自动化运维:得益于PD的智能调度,日常的负载均衡、副本管理、空间回收等工作全部自动化,极大地减轻了DBA的运维负担。
- 可视化监控:与Prometheus、Grafana深度集成,提供从集群整体到单个SQL语句粒度的全方位监控指标。
###
TiDB通过其清晰的分层架构——无状态的计算层(TiDB)、分布式强一致的存储层(TiKV)和智能的调度中心(PD),构建了一个既具备弹性扩展和高可用性,又提供强一致事务和实时分析能力的统一数据服务平台。其核心特性,尤其是HTAP能力,打破了传统数据库的边界,让企业能够在一个系统中应对快速增长的数据和多样化的业务负载,是构建现代数据密集型应用的坚实基石。对于寻求简化技术栈、应对海量数据挑战的团队而言,TiDB无疑是一个极具吸引力的选择。