随着大数据技术的飞速发展,传统的存算一体架构在面对海量数据处理需求时逐渐显现出瓶颈。存算分离作为一种新兴的架构模式,通过将数据存储与计算资源解耦,为大数据处理带来了更高的灵活性、可扩展性和成本效益。
一、存算分离的核心概念
存算分离是指将数据存储层与计算层独立部署和管理的一种架构设计。在这种模式下,数据持久化存储在专门的存储服务中,而计算任务则在独立的计算集群上执行,二者通过网络进行数据交互。这种分离使得存储和计算资源可以根据实际需求独立扩展,避免了资源浪费。
二、存算分离的优势
- 弹性扩展:存储和计算资源可以按需独立扩容,例如在数据量激增时仅扩展存储容量,而在计算密集型任务时增加计算节点。
- 成本优化:企业无需为存储和计算绑定采购硬件,可以根据使用情况灵活选择云服务或自有资源,降低总体拥有成本。
- 高可用性与容灾:分布式存储系统通常具备多副本和跨地域备份能力,结合计算层的故障转移机制,提升了系统的可靠性。
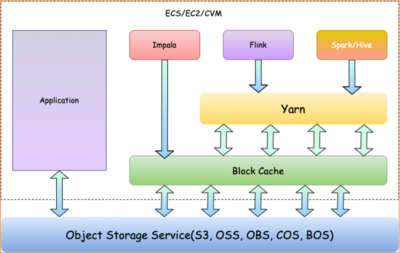
- 技术栈解耦:存储和计算可以采用不同的技术方案,例如使用对象存储(如AWS S3、阿里云OSS)结合大数据计算引擎(如Spark、Flink),实现最佳技术匹配。
三、数据处理与存储服务的实践
在存算分离架构下,数据处理流程通常分为以下几个步骤:
- 数据摄入:通过流式或批处理方式将数据写入分布式存储系统,如HDFS、云对象存储或数据库。
- 计算调度:计算引擎从存储层读取数据,执行ETL、分析或机器学习任务,结果写回存储层。
- 元数据管理:通过元数据服务(如Hive Metastore、AWS Glue)记录数据位置、格式和分区信息,方便计算层快速定位。
常见的存储服务包括:
- 对象存储:适用于非结构化数据,提供高持久性和低成本存储。
- 分布式文件系统:如HDFS,适合大规模批处理场景。
- 云原生数据库:如Snowflake、BigQuery,融合了存算分离理念,提供即席查询能力。
四、挑战与应对策略
尽管存算分离优势明显,但也面临一些挑战:
- 网络延迟:计算层与存储层之间的数据传输可能成为性能瓶颈。解决方案包括使用高速网络、数据本地化缓存(如Alluxio)或边缘计算。
- 数据一致性:在分布式环境下需保证读写一致性,可通过事务机制或最终一致性模型解决。
- 运维复杂度:分离架构需要更精细的监控和管理工具,建议采用自动化运维平台。
五、未来展望
随着云原生和容器化技术的普及,存算分离将进一步与Kubernetes等平台集成,实现更细粒度的资源调度。同时,智能数据分层、联邦计算等新技术将优化数据访问效率,推动存算分离成为大数据架构的主流选择。
存算分离通过重塑数据处理与存储的关系,为企业提供了更高效、经济的大数据解决方案。随着技术演进,它将在实时分析、AI应用等场景中发挥更大价值。